Tienes la web lista, currada, bien diseñada… pero por más que buscas, no aparece en Google. Empiezas a pensar que hay un problema serio y, probablemente, no vas mal encaminado. Cuando Google no indexa tu página, hay algo que está fallando. La buena noticia es que siempre tiene arreglo.
Si te estás preguntando por qué Google no indexa tu web, o por qué en Google Search Console no indexa ciertas URLs, sigue leyendo. Aquí te explicamos los problemas más comunes y qué puedes hacer para solucionarlos.

Mockup de Envato
Índice
¿Qué significa que Google no indexe tu página?
Si una página no está indexada, no existe para Google. Y si no existe para Google, no va a aparecer nunca en los resultados de búsqueda. Es decir, no tienes visibilidad orgánica, por muy buena que sea tu web o tu contenido.
Indexar es el proceso por el cual Google guarda tu página en su «biblioteca». Primero la rastrea (la visita), y luego decide si la indexa o no. Si decide que no, o ni siquiera llega a visitarla, esa url nunca va a aparecer en las búsquedas, sea lo que sea que busque el usuario. Eso es lo que significa que una página no está indexada por Google.
¿Por qué Google no indexa mi web?
Vamos al grano. Estas son las razones más habituales por las que te encuentras con páginas no indexadas por Google, algo con lo que las agencias SEO peleamos todos los días y que, para desgracia de todos, son mucho más comunes de lo que se puede pensar.
Tu web es nueva y Google aún no ha llegado
A veces, simplemente es cuestión de tiempo. Si acabas de lanzar tu sitio o has publicado nuevas URLs, Google aún no las ha rastreado. Esto puede tardar días o incluso semanas.
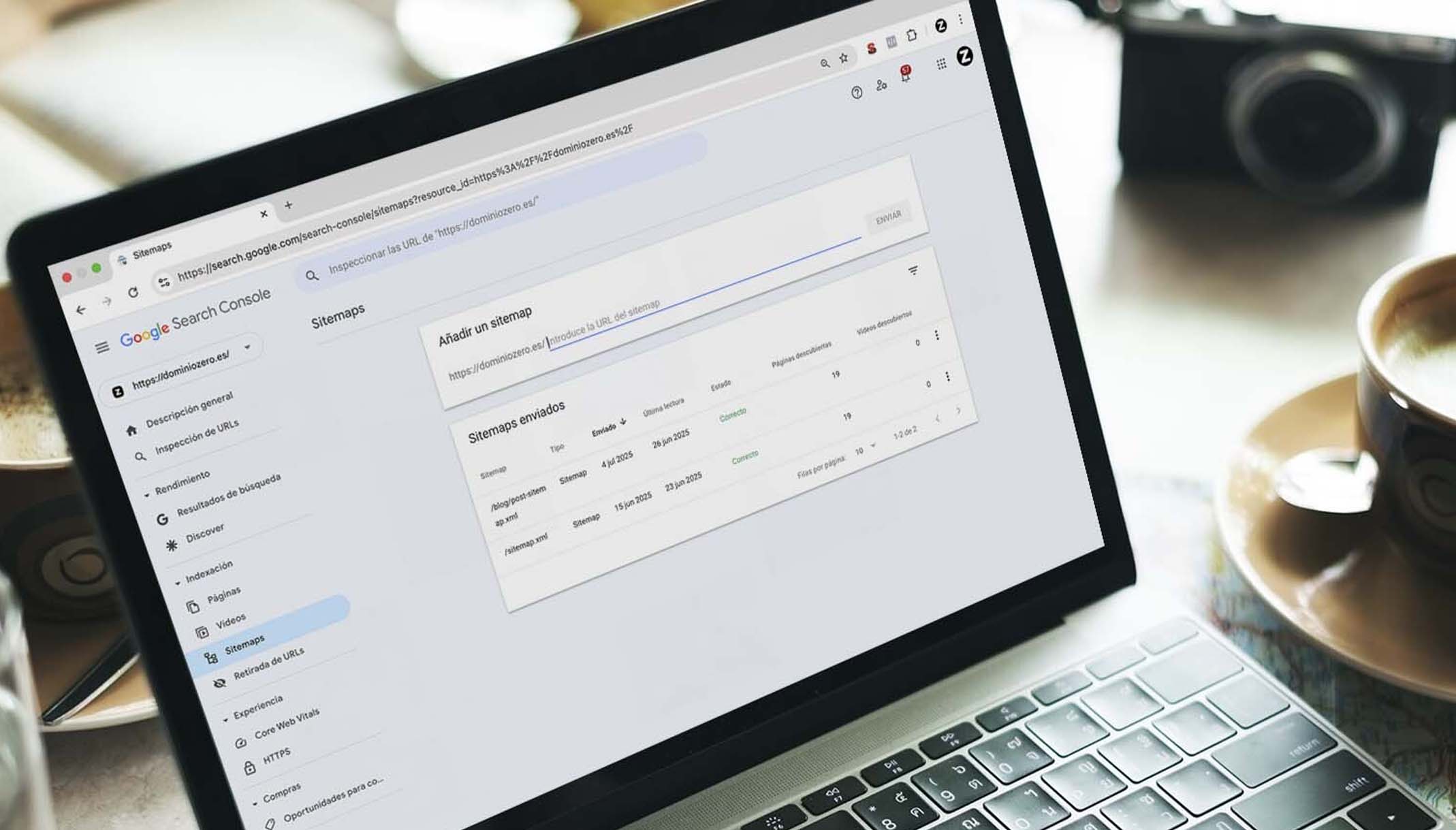
Aunque puedes esperar pacientemente a que los crawlers de Google visiten tu web de manera natural, lo mejor es «avisarles» nosotros de que existe, así como facilitarles el camino para que lleguen a ella.
¿Cómo se hace esto? Pues solicitando la indexación de manera manual a través de Google Search Console:
- Da de alta tu web en Google Search Console, si no lo has hecho. Puedes acceder en el siguiente enlace: https://search.google.com/search-console/welcome
- Envía la url del sitemap.xml (y asegúrate de que está correcto).
- Usa la opción “Inspeccionar url” (pegando la url en el buscador superior).
- Haz clic en “Solicitar indexación”.
Mockup de Envato
Otra opción si no puedes acceder a Search Console por lo que sea, es intentar que los crawlers lleguen de manera natural facilitándoles el camino. No es tan eficaz, pero es mejor que quedarse con los brazos cruzados esperando.
¿Y esto cómo?
Pues muy sencillo: publicando enlaces a nuestra web en todas las plataformas o medios que podamos, tanto sea a través de la gestión de redes sociales como con una nota de prensa de branding.
Es una buena práctica, ya que el enlazado externo (lo que los SEOs llamamos backlinking) es una de las mejores prácticas para mejorar la autoridad de una web. El enlazado interno también es muy beneficioso, pero para indexar sólo funciona en webs ya indexadas en las que se sube más contenido en urls
El archivo robots.txt bloquea el acceso
El robots.txt es un archivo que está en la raíz de tu dominio (tudominio.com/robots.txt) y sirve para decirle a los buscadores qué partes de tu web pueden rastrear y cuáles no.
El problema viene cuando este archivo bloquea sin querer páginas importantes, o directamente toda la web. Y claro, si Google no puede ni entrar, mucho menos va a indexar nada.
¿Cómo debería estar configurado el archivo robots.txt para que Google indexe una web?
Aquí tienes un ejemplo básico que permite el acceso a toda la web:
User-agent: * Disallow:
Eso le dice a todos los bots (“User-agent: *”) que no hay ninguna ruta prohibida (Disallow: está en blanco). Es la forma más abierta posible.
Ahora bien, si necesitas bloquear alguna carpeta concreta (por ejemplo, el panel de admin de WordPress), puedes hacerlo así:
User-agent: * Disallow: /wp-admin/
Esto bloquea solo esa carpeta (las urls que cumplen con esa regla), pero deja el resto de la web libre para ser rastreada e indexada.
¿Como NO deberías tener el robots.txt?
A menos que tengas un propósito específico y sepas bien lo que haces, hay que tener mucho ojo si empiezas a meter reglas o directrices de disallow, ya que si escribes alguna mal puedes impedir el rastreo de urls importantes o incluso de toda la web.
Un ejemplo que se ve mucho y que a simple vista parece inofensivo es el siguiente, pero con esta chorrada impedirías el rastreo de absolutamente todas las urls del dominio:
User-agent: *
Disallow: /Otro ejemplo es marcar como disallow toda una subcarpeta dentro del dominio, como el blog, por ejemplo. La regla que ves a continuación no afecta únicamente a la url de dominio.com/blog/, si no a todas las que hay dentro de esta carpeta: dominio.com/blog/post-1/, dominio.com/blog/post-2/… Tener esto en el robots.txt dificultaría con creces que estas páginas se indexen.
User-agent: * Disallow: /blog/
¡OJO! Disallow no es lo mismo que No-Index
El robots.txt funciona a modo recomendación. Google suele hacerle caso, pero hay veces en los que lo «pasa por alto» y, aunque pongas algo disallow, si Google llega a la url por otros medios (un enlace externo o interno) y considera que es relevante para el usuario, lo indexa igualmente.
Puede ser algo bueno (si tenemos el archivo robots.txt mal configurado) o malo (si indexa algo que no queremos, como un filtro o una búsqueda de productos).
¿Google pasa de tu web? Nosotros no.
Si Google no muestra tu web, tus clientes no la ven. Revisamos tu sitio, detectamos el problema y lo solucionamos.
Tienes una etiqueta "noindex" en el código
Este es uno de los fallos más comunes cuando Google no indexa mi página. A veces, sin darnos cuenta (o porque alguien activó la opción por defecto en un CMS y se olvidó de quitarla), le estamos diciendo a Google que no indexe una página con una etiqueta “noindex” incrustada en el head.
Inspecciona el código fuente de las páginas no indexadas por Google y busca en el <head> del HTML si hay una etiqueta como esta:
<meta name="robots" content="noindex">Si tienes esto puesto, he aquí el problema. Le estás indicando a Google que, aunque entre a leer tu página, que nunca la muestre en los resultados. Puede que sea algo intencionado, si todavía estás trabajando en tu página y no quieres que nadie llegue a ella o si es una página de poco valor (como el aviso legal o la política de privacidad), pero es algo imprescindible que hay que cambiar sí o sí si quieres que Google indexe tu página.
¿Y cómo se soluciona? Pues muy sencillo. Primero, tienes que localizar de qué manera está puesto ese «noindex»:
- Si está puesto a través de un módulo (Yoast Seo o alguno similar) sólo debes buscar la pestaña correspondiente («noindex» o la opción que dice “No permitir que los motores de búsqueda indexen esta página”) y cambiarla.
- Si está puesto de manera manual, cambia la línea de <meta name=’robots’ content=’noindex’> del HTML por lo siguiente:
<meta name="robots" content="index, follow">Si haces este cambio, en nuestra agencia de diseño web siempre recomendamos solicitar la indexación de la url en Search Console para intentar agilizar el proceso lo máximo posible.
No hay enlaces hacia esa página
Otra razón por la que Google no indexa una página puede ser simplemente porque no llega a ella. Google rastrea la web a través de enlaces y, si no hay ningún enlace que apunte a esa URL (ni desde dentro de tu web ni desde fuera), es muy probable que esa url se quede en el limbo y no la indexe, pero simplemente porque no la ve.
Si nadie le dice a Google que esa página existe, ¿cómo esperas que llegue hasta ella?
Algunos ejemplos muy típicos:
- Creas una landing para una campaña, pero no está enlazada desde el menú ni desde ningún otro sitio, red social ni página.
- Publicas un post en el blog y te olvidas de enlazarlo desde otras entradas, la home o la categoría correspondiente.
- Haces una página de servicios nueva y no la conectas con la navegación principal en el menú ni en ninguna otra url.
¿Y qué hay que hacer?
Lo primero es hacer una auditoría de enlazado interno. Usa herramientas como Screaming Frog, Ahrefs o incluso un Excel para ver qué páginas están enlazando a otras y cuáles no tienen enlaces entrantes, sin ningún enlace que apunten hacia ella.
Es importante incluir enlaces desde tu home, el menú, categorías, el footer o posts relacionados. Cuanto más enlaces haya hacia una página sea, más posibilidades tiene de ser rastreada e indexada.
Lo segundo más importante es conseguir enlaces externos (backlinks). No tienen que ser de medios enormes: un enlace desde un blog, foro o red social también ayuda a que Google llegue de manera más fácil a tu web.
Mockup de Envato
Tienes contenido de poco valor que no le interesa a Google
Google ya no indexa todo lo que se publica. Si tu contenido es flojo, duplicado de otro o no aporta nada nuevo, Google puede decidir que no merece la pena indexarlo. No es que esté roto ni haya algo mal, es que simplemente no le interesa.
Algunos ejemplos muy habituales:
- Textos muy cortos sin desarrollar (menos de 300-400 palabras y sin contexto).
- Contenido duplicado (copiado de otra web o de otras páginas dentro de la tuya).
- Páginas sin estructura: sin títulos claros, sin imágenes, sin jerarquía de información, listados sin más contexto…
Es importante trabajar bien cada página, creando contenido útil y que responda preguntas reales de tu público. Además, es fundamental evitar duplicados, tanto con otras webs como con otras páginas de tu propio sitio web. Si tienes muchas fichas de producto muy parecidas o con la de la competencia que vende lo mismo, añade descripciones únicas, FAQs, vídeos, etc.
Otro punto muy importante es añadir contexto y estructura a los textos: títulos con sentido, encabezados (<h2>, <h3>), listas, negritas, imágenes con texto alternativo. Que sean fáciles de leer tanto para los usuarios como para los crawlers de Google.
Penalizaciones o problemas técnicos graves
Cuando Google no indexa tu página y ya has descartado lo básico, es hora de mirar si el problema es más serio. A veces, lo que ocurre es que has entrado (sin querer o por ir demasiado rápido) en terreno de penalizaciones o errores técnicos gordos. Google tiene tolerancia cero con ciertas prácticas, y si detecta que estás haciendo trampas o que tu web es un caos técnico, puede dejar de indexarte como medida preventiva o correctiva.
Entre las causas más frecuentes están las malas prácticas SEO, como comprar demasiados enlaces de baja calidad y sin indicar que son patrocinios, abusar de palabras clave metidas con calzador, esconder contenido (lo que se conoce como cloaking) o publicar páginas generadas automáticamente sin control ni valor real.
Y no solo eso: a nivel técnico, una web con errores constantes, servidores lentos, fallos de rastreo, redirecciones mal hechas o una arquitectura mal planteada también puede acabar perjudicada en la indexación. Aunque no haya penalización manual, Google simplemente puede decidir no incluir esas páginas porque no cumplen con sus estándares mínimos de calidad.
La solución en este caso es más compleja, ya que es necesario hacer una auditoría técnica en profundidad, a nivel servidor y enlazado externo, para descubrir qué es lo que está pasando.
¿Y ahora qué hago si todavía Google no indexa mi página?
Llegados a este punto, ya sabes que cuando Google no indexa tu página, no es por capricho. Hay una serie de motivos (unos más simples, otros más técnicos) que pueden estar bloqueando el proceso.
Lo importante es entender que no aparecer en el índice de Google significa no existir para tus potenciales clientes. Da igual lo bien que esté diseñada tu web, el contenido que tengas o lo mucho que hayas invertido: si Google no te ve, nadie más lo hará.
Si te has leído todo esto y piensas: “Vale, ya sé por qué Google no indexa mi página, pero no sé, no tengo tiempo ni ganas de meterme en el barro”, es totalmente normal.
En nuestra agencia de marketing digital llevamos años solucionando estas historias. Podemos hacerte una auditoría express, revisar qué URLs están fuera del radar y darte un plan claro para arreglarlo y conseguir no solo que tu web se indexe en Google, si no que capte clientes.
¿Lo hablamos?